




So far in this series of posts, you have been able to deploy and configure your newly provisioned Azure Arc-enabled SQL MI environment. Out of the box you get High Availability without having to do or implement anything.
The Recovery Time Objective (RTO) that is achievable with Azure Arc-enabled Data Services is dependent on the tier you choose to deploy. But regardless of that, this post is only concerned about informing you what you get out of the box with this technology.
Just like all Azure Services, Azure Arc-enabled Data Services allow you to choose either General Purpose or Business Critical Tier deployments. We have already looked at this briefly as part of post 8 of this series. From a High Availability point of view the differences achievable with the available tiers are as follows:
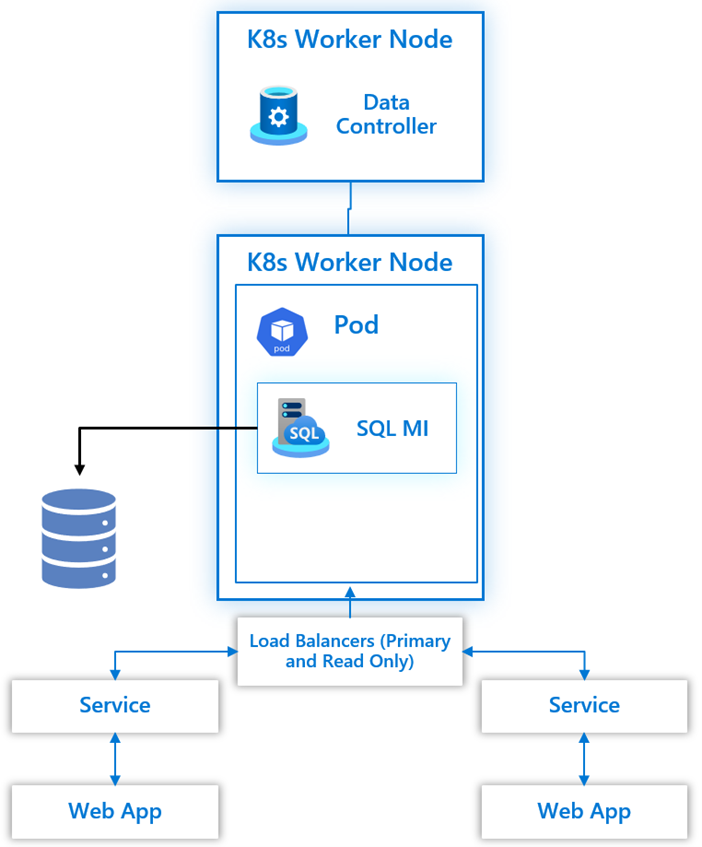
General Purpose Tier
In this tier an Arc-enabled SQL MI is deployed to a single Kubernetes pod with shared storage. In the event of an issue with the Kubernetes pod, a new pod is deployed with the arc-enabled SQL MI configured that then connects to the shared storage allowing for your applications to connect and continue functioning as required.
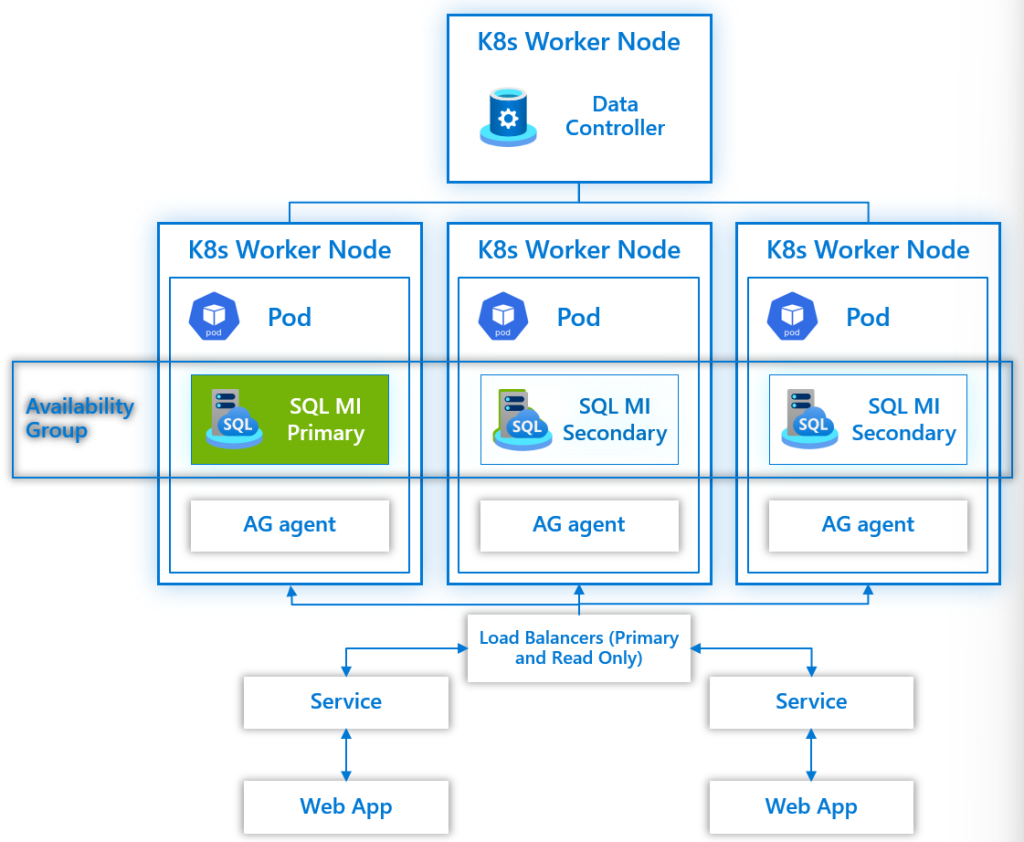
Business Critical Tier
In this tier an Arc-enabled SQL MI is deployed to up to three Kubernetes pods with dedicated storage for each pod. Contained Availability Groups are automatically configured and used to provide your High Availability. In the event of an issue with the Kubernetes pod, a failover is instigated, and your applications connect to the new primary replica. A new pod is deployed with the arc-enabled SQL MI configured that replaces the failed pod.
In our next post we will look at Disaster Recovery options for our Azure Arc-enabled SQL Managed Instance deployments.

Leave a Reply